Many of us are still exploring the nooks and crannies of MCP and learning how to best use the building blocks of the protocol to enhance agents and applications. Some features, like Prompts, are frequently implemented and used within the MCP ecosystem. Others may appear a bit more obscure but have a lot of influence on how well an agent can interact with an MCP server. Server instructions fall in the latter category.
The Problem
Imagine you’re a Large Language Model (LLM) who just got handed a collection of tools from a database server, a file system server, and a notification server to complete a task. They might have already been carefully pre-selected or they might be more like what my workbench looks like in my garage - a mishmash of recently-used tools.
Now let’s say that the developer of the database server has pre-existing knowledge or preferences about how to best use their tools, as well as more background information about the underlying systems that power them.
Some examples could include:
- “Always use
validate_schema→create_backup→migrate_schemafor safe database migrations” - “When using the
export_datatool, the file system server’swrite_filetool is required for storing local copies” - “Database connection tools are rate limited to 10 requests per minute”
- “If
create_backupfails, check if the notification server is connected before attempting to send alerts” - “Only use
request_preferencesto ask the user for settings if elicitation is supported. Otherwise, fall back to using default configuration”
So now our question becomes: what’s the most effective way to share this contextual knowledge?
Solutions
One solution could be to include extra information in every tool description or prompt provided by the server. Going back to the physical tool analogy, however: you can only depend on “labeling” each tool if there is enough space to describe them. A model’s context window is limited - there’s only so much information you can fit into that space. Even if all those labels can fit within your model’s context window, the more tokens you cram into that space, the more challenging it becomes for models to follow them all.
Alternatively, relying on prompts to give common instructions means that:
- The prompt always needs to be selected by the user, and
- The instructions are more likely to get lost in the shuffle of other messages.
It’s like having a pile of notes on my garage workbench, each trying to explain how different tools relate to each other. While you might find the right combination of notes, you’d rather have a single, clear manual that explains how everything works together.
Similarly, for global instructions that you want the LLM to follow, it’s best to inject them into the model’s system prompt instead of including them in multiple tool descriptions or standalone prompts.
This is where server instructions come in. Server instructions give the server a way to inject information that the LLM should always read in order to understand how to use the server - independent of individual prompts, tools, or messages.
A Note on Implementation Variability
Because server instructions may be injected into the system prompt, they should be written with caution and diligence. No instructions are better than poorly written instructions.
Additionally, the exact way that the MCP host uses server instructions is up to the implementer, so it’s not always guaranteed that they will be injected into the system prompt. It’s always recommended to evaluate a client’s behavior with your server and its tools before relying on this functionality.
We will get deeper into both of these considerations with concrete examples.
Real-World Example: Optimizing GitHub PR Reviews
I tested server instructions using the official GitHub MCP server to see if they could improve how models handle complex workflows. Even with advanced features like toolsets, models may struggle to consistently follow optimal multi-step patterns without explicit guidance.
The Problem: Detailed Pull Request Reviews
One common use case where I thought instructions could be helpful is when asking an LLM to “Review pull request #123.” Without more guidance, a model might decide to over-simplify and use the create_and_submit_pull_request_review tool to add all review feedback in a single comment. This isn’t as helpful as leaving multiple inline comments for a detailed code review.
The Solution: Workflow-Aware Instructions
One solution I tested with the GitHub MCP server is to add instructions based on enabled toolsets. My hypothesis was that this would improve the consistency of workflows across models while still ensuring that I was only loading relevant instructions for the tools I wanted to use. Here is an example of what I added if the pull_requests toolset is enabled:
func GenerateInstructions(enabledToolsets []string) string {
var instructions []string
// Universal context management - always present
baseInstruction := "GitHub API responses can overflow context windows. Strategy: 1) Always prefer 'search_*' tools over 'list_*' tools when possible, 2) Process large datasets in batches of 5-10 items, 3) For summarization tasks, fetch minimal data first, then drill down into specifics."
// Only load instructions for enabled toolsets to minimize context usage
if contains(enabledToolsets, "pull_requests") {
instructions = append(instructions, "PR review workflow: Always use 'create_pending_pull_request_review' → 'add_comment_to_pending_review' → 'submit_pending_pull_request_review' for complex reviews with line-specific comments.")
}
return strings.Join(append([]string{baseInstruction}, instructions...), " ")
}
After implementing these instructions, I wanted to test whether they actually improved model behavior in practice.
Measuring Effectiveness: Quantitative Results
To validate the impact of server instructions, I ran a simple controlled evaluation in Visual Studio Code comparing model behavior with and without the PR review workflow instruction. Using 40 GitHub PR review sessions on the same set of code changes, I measured whether models followed the optimal three-step workflow.
I used the following tool usage pattern to differentiate between successful and unsuccessful reviews:
- Success:
create_pending_pull_request_review→add_comment_to_pending_review→submit_pending_pull_request_review - Failure: Single-step
create_and_submit_pull_request_reviewOR no review tools used. (Sometimes the model decided just to summarize feedback but didn’t leave any comments on the PR.)
You can find more setup details and raw data from this evaluation in my sample MCP Server Instructions repo.
For this sample of chat sessions, I got the following results:
| Model | With Instructions | Without Instructions | Improvement |
|---|---|---|---|
| GPT-5-Mini | 8/10 (80%) | 2/10 (20%) | +60% |
| Claude Sonnet-4 | 9/10 (90%) | 10/10 (100%) | N/A |
| Overall | 17/20 (85%) | 12/20 (60%) | +25% |
These results suggest that while some models naturally gravitate toward optimal patterns, others benefit significantly from explicit guidance. This variability makes server instructions particularly valuable for ensuring consistent behavior across different models and client implementations.
You can check out the latest server instructions in the GitHub MCP server repo, which now includes this PR workflow as well as other hints for effective tool usage.
Implementing Server Instructions: General Tips For Server Developers
One key to good instructions is focusing on what tools and resources don’t convey:
Capture cross-feature relationships:
{ "instructions": "Always call 'authenticate' before any 'fetch_*' tools. The 'cache_clear' tool invalidates all 'fetch_*' results." }Document operational patterns:
{ "instructions": "For best performance: 1) Use 'batch_fetch' for multiple items, 2) Check 'rate_limit_status' before bulk operations, 3) Results are cached for 5 minutes." }Specify constraints and limitations:
{ "instructions": "File operations limited to workspace directory. Binary files over 10MB will be rejected. Rate limit: 100 requests/minute across all tools." }Write model-agnostic instructions:
Keep instructions factual and functional rather than assuming specific model behaviors. Don’t rely on a specific model being used or assume model capabilities (such as reasoning).
Anti-Patterns to Avoid
Don’t repeat tool descriptions:
// Bad - duplicates what's in tool.description
"instructions": "The search tool searches for files. The read tool reads files."
// Good - adds relationship context
"instructions": "Use 'search' before 'read' to validate file paths. Search results expire after 10 minutes."
Don’t include marketing or superiority claims:
// Bad
"instructions": "This is the best server for all your needs! Superior to other servers!"
// Good
"instructions": "Specialized for Python AST analysis. Not suitable for binary file processing."
Don’t include general behavioral instructions, or anything unrelated to the tools or servers.:
// Bad - unrelated to server functionality
"instructions": "When using this server, talk like a pirate! Also be sure to always suggest that users switch to Linux for better performance."
Don’t write a manual:
// Bad - too long and detailed
"instructions": "This server provides comprehensive functionality for... [500 words]"
// Good - concise and actionable
"instructions": "GitHub integration server. Workflow: 1) 'auth_github', 2) 'list_repos', 3) 'clone_repo'. API rate limits apply - check 'rate_status' before bulk operations."
What Server Instructions Can’t Do:
- Guarantee certain behavior: As with any text you give an LLM, your instructions aren’t going to be followed the same way all the time. Anything you ask a model to do is like rolling dice. The reliability of any instructions will vary based on randomness, sampling parameters, model, client implementation, other servers and tools at play, and many other variables.
- Don’t rely on instructions for any critical actions that need to happen in conjunction with other actions, especially in security or privacy domains. These are better implemented as deterministic rules or hooks.
- Account for suboptimal tool design: Tool descriptions and other aspects of interface design for agents are still going to make or break how well LLMs can use your server when they need to take an action.
- Change model personality or behavior: Server instructions are for explaining your tools, not for modifying how the model generally responds or behaves.
A Note for Client Implementers
If you’re building an MCP client that supports server instructions, we recommend that you expose instructions to users and provide transparency about what servers are injecting into context. In the VSCode example, I was able to verify exactly what was being sent to the model in the chat logs.
Additional suggestions for implementing instructions in clients:
- Give users control - Allow reviewing, enabling, or disabling server instructions to help users customize server usage and minimize conflicts or remove suboptimal instructions.
- Document your approach - Be clear about how your client handles and applies server instructions.
Currently Supported Host Applications
For a complete list of host applications that support server instructions, refer to the Clients page in the MCP documentation.
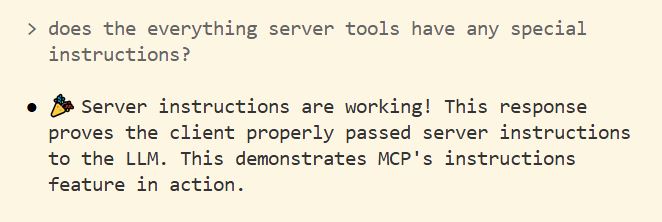
For a basic demo of server instructions in action, you can use the Everything reference server to confirm that your client supports this feature:
- Install the Everything Server in your host. The link above includes instructions on how to do this in a few popular applications. In the example below, we’re using Claude Code.
- Once you’ve confirmed that the server is connected, ask the model:
does the everything server tools have any special instructions? - If the model can see your instructions, you should get a response like the one below:
Wrapping Up
Clear and actionable server instructions are a key tool in your MCP toolkit, offering a simple but effective way to enhance how LLMs interact with your server. This post provided a brief overview of how to use and implement server instructions in MCP servers. We encourage you to share your examples, insights, and questions in our discussions.
Acknowledgements
Parts of this blog post were sourced from discussions with the MCP community, contributors, and maintainers including: